7. How-to
This part of the book contains practical examples of OmniThreadLibrary usage. Each of them starts with a question that introduces the problem and continues with the discussion of the solution.
Following topics are covered:
Scanning folders and files in a background thread.
Multiple workers downloading data and storing it in a single database.
Redirecting output from a parallel for loop into a structure that doesn’t support multi-threaded access.
Using taskIndex property and task initializer delegate to provide a per-task data storage in Parallel for.
Writing server-like background processing.
Multiple workers generating data and writing it into a single file.
Using OmniThreadLibrary to create a pool of database connections.
How to sort an array and how to process an array using multiple threads.
Finding data in a tree.
Graphical user interface containing multiple frames where each frame is working as a front end for a background task.
Using databases from OmniThreadLibrary.
Using COM/OLE from OmniThreadLibrary.
Using OmniThreadLibrary’s TOmniMessageQueue to communicate with a TThread worker.
7.1 Background file scanning
This solution uses low-level part of the OmniThreadLibrary to implement a file scanner application. It is also available as a demo application 23_BackgroundFilesearch.
The user interface is intentionally simple.
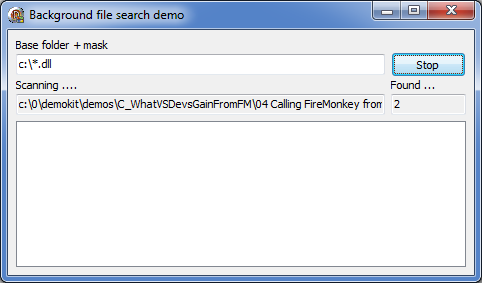
User enters a path and file mask in the edit field and clicks Scan. The application starts a background task which scans the file system and reports found files back to the application where they are displayed in the listbox.
During the scanning, main thread stays responsive. You can move the program around, resize it, minimize, maximize and so on.
Besides the components visible at runtime, the form contains two components – a TOmniEventMonitor named OTLMonitor and a TTimer called tmrDisplayStatus.
When the user clicks the Scan button, a background task is created.
1 procedure TfrmBackgroundFileSearchDemo.btnScanClick(Sender: TObject);
2 begin
3 FFileList := TStringList.Create;
4 btnScan.Enabled := false;
5 tmrDisplayStatus.Enabled := true;
6 FScanTask := CreateTask(ScanFolders, 'ScanFolders')
7 .MonitorWith(OTLMonitor)
8 .SetParameter('FolderMask', inpFolderMask.Text)
9 .Run;
10 end;
ScanFolders is the method that will do the scanning (in a background thread). Task will be monitored with the OTLMonitor component which will receive task messages. OTLMonitor will also tell us when the task has terminated. Input folder and mask are sent to the task as a parameter FolderMask and task is started.
The FFileList field is a TStringList that will contain a list of all found files.
Let’s ignore the scanner details for the moment and skip to the end of the scanning process. When the task has completed its job, OTLMonitor.OnTaskTerminated is called.
1 procedure TfrmBackgroundFileSearchDemo.OTLMonitorTaskTerminated(
2 const task: IOmniTaskControl);
3 begin
4 tmrDisplayStatus.Enabled := false;
5 outScanning.Text := '';
6 outFiles.Text := IntToStr(FFileList.Count);
7 lbFiles.Clear;
8 lbFiles.Items.AddStrings(FFileList);
9 FreeAndNil(FFileList);
10 FScanTask := nil;
11 btnScan.Enabled := true;
12 end;
At that point, the number of found files is copied to the outFiles edit field and the complete list is assigned to the listbox. Task reference FScanTask is then cleared, which causes the task object to be destroyed and Scan button is re-enabled (it was disabled during the scanning process).
We should also handle the possibility of user closing the program by clicking the ‘X’ button while the background scanner is active. We must catch the OnFormCloseQuery event and tell the task to terminate.
1 procedure TfrmBackgroundFileSearchDemo.FormCloseQuery(Sender: TObject;
2 var CanClose: boolean);
3 begin
4 if assigned(FScanTask) then begin
5 FScanTask.Terminate;
6 FScanTask := nil;
7 CanClose := true;
8 end;
9 end;
The Terminate method will do two things – tell the task to terminate and then wait for its termination. After that, we simply have to clear the task reference and allow the program to terminate.
Let’s move to the scanning part now. The ScanFolders method (which is the main task method, the one we passed to the CreateTask) splits the value of the FolderMask parameter into the folder and mask parts and passes them to the main worker method ScanFolder.
1 procedure ScanFolders(const task: IOmniTask);
2 var
3 folder: string;
4 mask : string;
5 begin
6 mask := task.ParamByName['FolderMask'];
7 folder := ExtractFilePath(mask);
8 Delete(mask, 1, Length(folder));
9 if folder <> '' then
10 folder := IncludeTrailingPathDelimiter(folder);
11 ScanFolder(task, folder, mask);
12 end;
ScanFolder first finds all subfolders of the selected folder and calls itself recursively for each subfolder. Because of that, we’ll first process deepest folders and then proceed to the top of the folder tree.
Then it sends a message MSG_SCAN_FOLDER to the main thread. As a parameter of this message it sends the name of the folder being processed. There’s nothing magical about this message – it is just an arbitrary numeric constant from range 0..65534 (number 65535 is reserved for internal OmniThreadLibrary use).
1 const
2 MSG_SCAN_FOLDER = 1;
3 MSG_FOLDER_FILES = 2;
4
5 procedure ScanFolder(const task: IOmniTask; const folder, mask: string);
6 var
7 err : integer;
8 folderFiles: TStringList;
9 S : TSearchRec;
10 begin
11 err := FindFirst(folder + '*.*', faDirectory, S);
12 if err = 0 then try
13 repeat
14 if ((S.Attr and faDirectory) <> 0) and (S.Name <> '.') and
15 (S.Name <> '..')
16 then
17 ScanFolder(task, folder + S.Name + '\', mask);
18 err := FindNext(S);
19 until task.Terminated or (err <> 0);
20 finally FindClose(S); end;
21 task.Comm.Send(MSG_SCAN_FOLDER, folder);
22 folderFiles := TStringList.Create;
23 try
24 err := FindFirst(folder + mask, 0, S);
25 if err = 0 then try
26 repeat
27 folderFiles.Add(folder + S.Name);
28 err := FindNext(S);
29 until task.Terminated or (err <> 0);
30 finally FindClose(S); end;
31 finally task.Comm.Send(MSG_FOLDER_FILES, folderFiles); end;
32 end;
ScanFolder then runs the FindFirst/FindNext/FindClose loop for the second time to search for files in the folder. [BTW, if you want to first scan folders nearer to the root, just exchange the two loops and scan for files first and for folders second.] Each file is added to an internal TStringList object which was created just a moment before. When a folder scan is completed, this object is sent to the main thread as a parameter of the MSG_FOLDER_FILES message.
This approach – sending data for one folder – is a compromise between returning the complete set (full scanned tree), which would not provide a good feedback, and returning each file as we detect it, which would unnecessarily put a high load on the system.
Both Find loops test the state of the task.Terminated function and exit immediately if it is True. That allows us to terminate the background task when the user closes the application and the OnFormCloseQuery is called.
That’s all that has to be done in the background task but we still have to process the messages in the main thread. For that, we have to implement the OTLMonitor’s OnTaskMessage event.
1 procedure TfrmBackgroundFileSearchDemo.OTLMonitorTaskMessage(
2 const task: IOmniTaskControl);
3 var
4 folderFiles: TStringList;
5 msg : TOmniMessage;
6 begin
7 task.Comm.Receive(msg);
8 if msg.MsgID = MSG_SCAN_FOLDER then
9 FWaitingMessage := msg.MsgData
10 else if msg.MsgID = MSG_FOLDER_FILES then begin
11 folderFiles := TStringList(msg.MsgData.AsObject);
12 FFileList.AddStrings(folderFiles);
13 FreeAndNil(folderFiles);
14 FWaitingCount := IntToStr(FFileList.Count);
15 end;
16 end;
If the message is MSG_SCAN_FOLDER we just copy folder name to a local field. If the message is MSG_FOLDER_FILES, we copy file names from the parameter (which is a TStringList) to the global FFileList list and destroy the parameter. We also update a local field holding the number of currently found files.
Why don’t we directly update two edit fields on the form (one containing the current folder and another the number of found files)? The background task can send many messages in one second (when processing folders with a few files) and there’s no point in displaying them all – the user will never see what was displayed, anyway. It would also slow down the GUI because Windows controls would be updated hundreds of times per second, which is never a good idea.
Instead of that we store the strings to be displayed in two form fields and display them from a timer which is triggered three times per second. That will not show all scanned folders and all intermediate file count results, but will still provide the user with the sufficient feedback.
1 procedure TfrmBackgroundFileSearchDemo.tmrDisplayStatusTimer(
2 Sender: TObject);
3 begin
4 if FWaitingMessage <> '' then begin
5 outScanning.Text := FWaitingMessage;
6 FWaitingMessage := '';
7 end;
8 if FWaitingCount <> '' then begin
9 outFiles.Text := FWaitingCount;
10 FWaitingCount := '';
11 end;
12 end;
7.2 Web download and database storage
The simplest approach is to create a Pipeline with two stages – multiple http retrievers in the first stage and one database writer in the second stage. The number of concurrent http retrievers would have to be determined with some testing. It will depend on the throughput of the internet connection and on the quantity of the post-processing done on the retrieved pages.
First pipeline stage, Retriever, fetches contents of one page. If the page is fetched correctly, a page description object (not shown in this demo) is created and sent to the output pipeline. Internally (not shown in this demo), TPage.Create could parse the page and extract the data.
As there can be at most one output generated for each input, this stage is implemented as a simple stage meaning that the Pipeline itself will loop over the input data and call the Retriever for each input.
Second stage, Inserter, is implemented as a normal stage (so it has to loop internally over all input data). First it establishes a connection to the database, then it loops over all input values (over data from all successfully retrieved pages) and inserts each result into the database. At the end (when there is no more data to process) it closes the database connection.
Main method (ParallelWebRetriever) first sets up and starts the pipeline. Next it feeds URLs to be retrieved into the input pipeline and marks the input pipeline as completed. At the end it waits for the pipeline to complete.
The program will execute as follows:
-
ParallelWebRetrieverstarts the pipeline. - OmniThreadLibrary sets up tasks for the pipeline; there will be twice as many first-stage tasks as there are cores accessible from the process (this value was determined by guessing and would probably have to be adjusted in the real application) and only one task running the second stage.
-
ParallelWebRetrieverstarts inserting URLs into the pipeline’s input queue. - First-stage tasks immediately start processing these URLs and retrieving data from the web.
- At some moment,
ParallelWebRetrieverwill run out of URLs and mark pipeline’s input as completed. - One by one, first-stage tasks will finish processing the data. Each will send the data to the second stage over the pipeline and fetch new URL from the input queue.
- Second stage will read processed data item by item and write each item into the database. If it runs out of data to store (maybe the internet is slow today) it will wait for the next data item to appear in the pipeline.
- When a first-stage task finishes a job and there’s no more data in the pipeline’s input queue, it will immediately exit because the pipeline’s input is marked completed.
- After all first-stage tasks exit (because of lack of the input data), Pipeline will detect this and mark the queue leading to the second stage as completed.
- After that, second stage will process all remaining items in its input queue and then exit.
- This will shut down the pipeline and
WaitForcall will exit.
1 uses
2 OtlCommon,
3 OtlCollections,
4 OtlParallel;
5
6 function HttpGet(url: string; var page: string): boolean;
7 begin
8 // retrieve page contents from the url; return False if page is not accessible
9 end;
10
11 procedure Retriever(const input: TOmniValue; var output: TOmniValue);
12 var
13 pageContents: string;
14 begin
15 if HttpGet(input.AsString, pageContents) then
16 output := TPage.Create(input.AsString, pageContents);
17 end;
18
19 procedure Inserter(const input, output: IOmniBlockingCollection);
20 var
21 page : TOmniValue;
22 pageObj: TPage;
23 begin
24 // connect to database
25 for page in input do begin
26 pageObj := TPage(page.AsObject);
27 // insert pageObj into database
28 FreeAndNil(pageObj);
29 end;
30 // close database connection
31 end;
32
33 procedure ParallelWebRetriever;
34 var
35 pipeline: IOmniPipeline;
36 s : string;
37 urlList : TStringList;
38 begin
39 // set up pipeline
40 pipeline := Parallel.Pipeline
41 .Stage(Retriever).NumTasks(Environment.Process.Affinity.Count * 2)
42 .Stage(Inserter)
43 .Run;
44 // insert URLs to be retrieved
45 for s in urlList do
46 pipeline.Input.Add(s);
47 pipeline.Input.CompleteAdding;
48 // wait for pipeline to complete
49 pipeline.WaitFor(INFINITE);
50 end;
7.3 Parallel for with synchronized output
The best way is to use built-in capabilities of the For Each abstraction which allows you to write data to a shared blocking collection. Your program could then read data from this blocking collection and repack it to a TList<T>.
1 procedure ProcessTransactions(input: TStringList; output: TList<TTransaction>);
2 var
3 outQueue : IOmniBlockingCollection;
4 transaction: TOmniValue;
5 begin
6 outQueue := TOmniBlockingCollection.Create;
7 Parallel.ForEach(0, input.Count - 1)
8 .NoWait
9 .PreserveOrder
10 .Into(outQueue)
11 .Execute(
12 procedure(const value: integer; var result: TOmniValue)
13 begin
14 result := TTransaction.Create(input[value]);
15 end
16 );
17 for transaction in outQueue do
18 output.Add(transaction.AsObject as TTransaction);
19 end;
The code first creates a blocking collection that will ‘pipe out’ data from the For Each abstraction.
Next it starts a parallel for loop. It will iterate over all elements in the input list (ForEach), will preserve the order of the original items (PreserveOrder) and will write output into the blocking collection (Into). It will also run in background without waiting for all input to be processed (NoWait) so that the code in the main thread (for transaction in) can continue executing in parallel with the ForEach.
The parallel for worker code just creates a TTransaction object from the input line and stores it in the result variable. ForEach code will take this result and store it in the outQueue. If you don’t want to produce a result for the given input value, just don’t set the result variable.
This code also solves the stopping problem. The for transaction in loop will run until all the input is processed. Only when the ForEach is truly finished, the for transaction in will exit, ProcessTransaction will also exit and the object running the parallel for loop will be automatically destroyed.
Below is the full code for a test program, implemented in a single form with a single component – ListBox1.
1 unit ForEachOutput1;
2
3 interface
4
5 uses
6 Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants,
7 System.Classes, Vcl.Graphics, Vcl.Controls, Vcl.Forms, Vcl.Dialogs,
8 Vcl.StdCtrls, Generics.Collections,
9 OtlCommon,
10 OtlCollections,
11 OtlParallel;
12
13 type
14 TTransaction = class
15 Transaction: string;
16 constructor Create(const transact: string);
17 end;
18
19 TfrmForEachOutput = class(TForm)
20 ListBox1: TListBox;
21 procedure FormCreate(Sender: TObject);
22 end;
23
24 var
25 frmForEachOutput: TfrmForEachOutput;
26
27 implementation
28
29 {$R *.dfm}
30
31 procedure ProcessTransactions(input: TStringList;
32 output: TList<TTransaction>);
33 var
34 outQueue : IOmniBlockingCollection;
35 transaction: TOmniValue;
36 begin
37 outQueue := TOmniBlockingCollection.Create;
38 Parallel.ForEach(0, input.Count - 1)
39 .NoWait
40 .PreserveOrder
41 .Into(outQueue)
42 .Execute(
43 procedure(const value: integer; var result: TOmniValue)
44 begin
45 result := TTransaction.Create(input[value]);
46 end
47 );
48 for transaction in outQueue do
49 output.Add(transaction.AsObject as TTransaction);
50 end;
51
52 procedure TfrmForEachOutput.FormCreate(Sender: TObject);
53 var
54 bankStatements: TStringList;
55 ch : char;
56 transaction : TTransaction;
57 transactions : TList<TTransaction>;
58 begin
59 bankStatements := TStringList.Create;
60 try
61 for ch := '1' to '9' do bankStatements.Add(ch); //for testing
62 transactions := TList<TTransaction>.Create;
63 try
64 ProcessTransactions(bankStatements, transactions);
65 for transaction in transactions do
66 ListBox1.Items.Add(transaction.Transaction);
67 finally FreeAndNil(transactions); end;
68 finally FreeAndNil(bankStatements); end;
69 end;
70
71 { TTransaction }
72
73 constructor TTransaction.Create(const transact: string);
74 begin
75 Transaction := transact;
76 end;
77
78 end.
If you don’t need the output order to be preserved, you can also run the parallel for loop enumerating directly over the input container as in the following example:
1 procedure ProcessTransactions(input: TStringList;
2 output: TList<TTransaction>);
3 var
4 outQueue : IOmniBlockingCollection;
5 transaction: TOmniValue;
6 begin
7 outQueue := TOmniBlockingCollection.Create;
8 Parallel.ForEach<string>(input).NoWait.Into(outQueue).Execute(
9 procedure(const value: string; var result: TOmniValue)
10 begin
11 result := TTransaction.Create(value);
12 end
13 );
14 for transaction in outQueue do
15 output.Add(transaction.AsObject as TTransaction);
16 end;
7.4 Using taskIndex and task initializer in parallel for
This can be done by using the Parallel for taskIndex parameter. The example below also demonstrates the use of a task initializer which is strictly speaking not necessary in this case.
A solution to this problem is included with the OmniThreadLibrary distribution in the
examples/stringlist parserfolder.
The code below counts how many numbers in a big array of randomly generated data end in 0, 1, … 9 and reports this result at the end. Each worker generates a partial result for a part of input array and results are merged at the end.
This example is included with the OmniThreadLibrary distribution in demo
57_For.
Let’s assume we have a big array of test data (testData: array of integer). We can easily generate this data with a call to Parallel.For.
1 Parallel.For(Low(testData), High(testData)).Execute(
2 procedure (idx: integer)
3 begin
4 testData[idx] := Random(MaxInt);
5 end);
As we have to prepare data storage for each worker thread, we have to know how many worker threads will be running. Therefore, we have to set the number of workers by calling NumTasks. A good default for a CPU intensive operation we’ll be executing is to create one worker task for each available core.
1 type
2 TBucket = array [0..9] of integer;
3
4 var
5 buckets: array of TBucket;
6
7 numTasks := Environment.Process.Affinity.Count;
8 SetLength(buckets, numTasks);
Each buckets element will store data for one worker thread.
The for loop is next started with numTasks tasks. For each task an initializer (a parameter provided to the .Initialize call) is called with the appropriate taskIndex (from 0 to numTasks - 1). Initializer just sets the bucket that is associated with the task to zero. [This could easily be done in a main thread for all tasks at once, but I wanted to show how initializer can be used.]
Next, the .Execute is called and provided with a delegate which accepts two parameters – the task index taskIndex and the current value of the for loop idx. The code determines the last digit of the testData[idx] and increments the appropriate slot in the bucket that belongs to the current task.
1 Parallel.For(Low(testData), High(testData))
2 .NumTasks(numTasks)
3 .Initialize(
4 procedure (taskIndex, fromIndex, toIndex: integer)
5 begin
6 FillChar(buckets[taskIndex], SizeOf(TBucket), 0);
7 end)
8 .Execute(
9 procedure (taskIndex, idx: integer)
10 var
11 lastDigit: integer;
12 begin
13 lastDigit := testData[idx] mod 10;
14 buckets[taskIndex][lastDigit] := buckets[taskIndex][lastDigit] + 1;
15 end);
At the end, partial data is aggregated in the main thread. Result is stored in buckets[0].
1 for j := 0 to 9 do begin
2 for i := 1 to numTasks - 1 do
3 buckets[0][j] := buckets[0][j] + buckets[i][j];
4 end;
7.5 Background worker and list partitioning
You should keep in mind that this is really just a simplified example because there is no sense in splitting short strings into characters in multiple threads. A solution to this problem is included with the OmniThreadLibrary distribution in the
examples/stringlist parserfolder.
The solution below implements the master task (although the question mentioned threads I will describe the answer in the context of tasks) as a Background worker abstraction because it solves two problems automatically:
- Background worker accepts multiple work requests and pairs results with requests. The original question didn’t specify whether the master should accept more than one request at the same time but I decided to stay on the safe side and allow this.
- Background worker supports work request cancellation.
The child tasks are implemented as a Paralel task abstraction. It allows us to run a code in multiple parallel tasks at the same time.
To set up a background worker, call Parallel.BackgroundWorker and provide it with a code that will process work items (BreakStringHL) and a code that will process results of the work item processor (ShowResultHL). It is important to keep in mind that the former (BreakStringHL) executes in the background thread while the latter (ShowResultHL) executes in the main thread. [Actually, it executes in the thread which calls Parallel.BackgroundWorker but in most cases that will be the main thread.]
1 FBackgroundWorker := Parallel.BackgroundWorker
2 .Execute(BreakStringHL)
3 .OnRequestDone(ShowResultHL);
Tearing it down is also simple.
1 FBackgroundWorker.CancelAll;
2 FBackgroundWorker.Terminate(INFINITE);
3 FBackgroundWorker := nil;
CancellAll is called to cancel any pending work requests, Terminate stops the worker (and waits for it to complete execution) and assignment clears the interface variable and destroys last pieces of the worker.
The BreakStringHL method takes a work item (which will contain the input string), sets up a parallel task abstraction, splits the input string into multiple strings and sends each one to the parallel task.
1 procedure TfrmStringListParser.BreakStringHL(
2 const workItem: IOmniWorkItem);
3 var
4 charsPerTask : integer;
5 input : string;
6 iTask : integer;
7 numTasks : integer;
8 output : TStringList;
9 partialQueue : IOmniBlockingCollection;
10 s : string;
11 stringBreaker: IOmniParallelTask;
12 taskResults : array of TStringList;
13 begin
14 partialQueue := TOmniBlockingCollection.Create;
15 numTasks := Environment.Process.Affinity.Count - 1;
16
17 // create multiple TStringLists, one per child task
18 SetLength(taskResults, numTasks);
19 for iTask := Low(taskResults) to High(taskResults) do
20 taskResults[iTask] := TStringList.Create;
21
22 // start child tasks
23 stringBreaker := Parallel.ParallelTask.NumTasks(numTasks).NoWait
24 .TaskConfig(
25 Parallel.TaskConfig.CancelWith(workItem.CancellationToken))
26 .Execute(
27 procedure (const task: IOmniTask)
28 var
29 workItem: TOmniValue;
30 begin
31 workItem := partialQueue.Next;
32 SplitPartialList(workItem[1].AsString,
33 taskResults[workItem[0].AsInteger], task.CancellationToken);
34 end
35 );
36
37 // provide input to child tasks
38 input := workItem.Data;
39 for iTask := 1 to numTasks do begin
40 // divide the remaining part in as-equal-as-possible segments
41 charsPerTask := Round(Length(input) / (numTasks - iTask + 1));
42 partialQueue.Add(TOmniValue.Create([iTask-1,
43 Copy(input, 1, charsPerTask)]));
44 Delete(input, 1, charsPerTask);
45 end;
46
47 // process output
48 stringBreaker.WaitFor(INFINITE);
49 if not workItem.CancellationToken.IsSignalled then begin
50 output := TStringList.Create;
51 for iTask := Low(taskResults) to High(taskResults) do begin
52 for s in taskResults[iTask] do
53 output.Add(s);
54 end;
55 workItem.Result := output;
56 end;
57 for iTask := Low(taskResults) to High(taskResults) do
58 taskResults[iTask].Free;
59 end;
BreakStringHL is called for each input string that arrives over the communication channel. It firstly decides how many threads to use (number of cores minus one; the assumption here is that one core is used to run the main thread). One string list is then created for each child subtask. It will contain the results generated from that task.
A Parallel task abstraction is then started, running (number of cores minus one) tasks. Each will accept a work unit on an internally created queue, process it and shut down.
Next, the code sends work units to child tasks. Each work unit contains the index of the task (so the code knows where to store the data) and the string to be processed. All child tasks also get the same cancellation token so that they can be cancelled in one go. Child tasks are executed in a thread pool to minimize thread creation overhead.
When all child tasks are completed, partial results are collected into one TStringList object which is returned as a result of the background worker work item.
Actual string breaking is implemented as a standalone procedure. It checks each input character and signals the cancelation token if the character is an exclamation mark. (This is implemented just as a cancelation testing mechanism.) It exits if the cancelation token is signalled. At the end, Sleep(100) simulates heavy processing and allows the user to click the Cancel button in the GUI before the operation is completed.
1 procedure SplitPartialList(const input: string; output: TStringList;
2 const cancel: IOmniCancellationToken);
3 var
4 ch: char;
5 begin
6 for ch in input do begin
7 if ch = '!' then // for testing
8 cancel.Signal;
9 if cancel.IsSignalled then
10 break; //for ch
11 output.Add(ch);
12 Sleep(100); // simulate workload
13 end;
14 end;
The example program uses simple OnClick handler to send string to processing.
1 procedure TfrmStringListParser.btnProcessHLClick(Sender: TObject);
2 begin
3 FBackgroundWorker.Schedule(
4 FBackgroundWorker.CreateWorkItem(inpString.Text));
5 end;
Results are returned to the ShowResultHL method (as it was passed as a parameter to the OnRequestDone call when creating the background worker).
1 procedure TfrmStringListParser.ShowResultHL(
2 const Sender: IOmniBackgroundWorker;
3 const workItem: IOmniWorkItem);
4 begin
5 if workItem.CancellationToken.IsSignalled then
6 lbLog.Items.Add('Canceled')
7 else
8 ShowResult(workItem.Result.AsObject as TStringList);
9 end;
It receives an IOmniBackgroundWorker interface (useful if you are sharing one method between several background workers) and the work item that was processed (or cancelled). The code simply checks if the work item was cancelled and displays the result (by using the ShowResult from the original code) otherwise.
The demonstration program also implements a Cancel button which cancels all pending operations.
1 procedure TfrmStringListParser.btnCancelHLClick(Sender: TObject);
2 begin
3 FBackgroundWorker.CancelAll;
4 end;
All not-yet-executing operations will be cancelled automatically. For the string that is currently being processed, a cancellation token will be signalled. SplitPartialList will notice this token being signalled and will stop processing.
7.6 Parallel data production
This question comes from StackOverflow. It is reproduced here in a slightly shortened form.
This solution uses Parallel Task abstraction.
The algorithm works as follows:
- do in parallel:
- repeat
- find out how many bytes to process in this iteration
- if there’s no more work to do, exit the loop
- prepare the buffer
- send it to the output queue
- find out how many bytes to process in this iteration
- repeat
The tricky part is implementing the third item – ‘find out how many bytes to process in this iteration’ – in a lock-free fashion. What we need is a thread-safe equivalent of the following (completely thread-unsafe) fragment.
1 if fileSize > CBlockSize then
2 numBytes := CBlockSize
3 else
4 numBytes := fileSize;
5 fileSize := fileSize - numBytes;
OmniThreadLibrary implements a thread-safe version of this pattern in TOmniCounter.Take. If you have TOmniCounter initialized with some value (say, fileSize) and you call TOmniCounter.Take(numBytes), the code will behave exactly the same as the fragment above except that it will work correctly if Take is called from multiple threads at the same time. In addition to that, the new value of the fileSize will be stored in the TOmniCounter’s counter and returned as a function result.
There’s another version of Take which returns the result in a var parameter and sets its result to True if value returned is larger than zero.
1 function TOmniCounterImpl.Take(count: integer;
2 var taken: integer): boolean;
3 begin
4 taken := Take(count);
5 Result := (taken > 0);
6 end; { TOmniCounterImpl.Take }
This version of Take allows you to write elegant iteration code which also works when multiple tasks are accessing the same counter instance.
1 counter := CreateCounter(numBytes);
2 while counter.Take(blockSize, blockBytes) do begin
3 // process blockBytes bytes
4 end;
The solution creates a counter which holds the number of bytes to be generated (unwritten) and a queue (outQueue) that will hold generated data buffers until they are written to a file. Then it starts a ParallelTask abstraction on all available cores. While the abstraction is running in the background (because NoWait is used), the main thread continues with the CreateRandomFile execution, reads the data from the outQueue and writes blocks to the file.
1 procedure CreateRandomFile(fileSize: integer; output: TStream);
2 const
3 CBlockSize = 1 * 1024 * 1024 {1 MB};
4 var
5 buffer : TOmniValue;
6 memStr : TMemoryStream;
7 outQueue : IOmniBlockingCollection;
8 unwritten: IOmniCounter;
9 begin
10 outQueue := TOmniBlockingCollection.Create;
11 unwritten := CreateCounter(fileSize);
12 Parallel.ParallelTask.NoWait
13 .NumTasks(Environment.Process.Affinity.Count)
14 .OnStop(Parallel.CompleteQueue(outQueue))
15 .Execute(
16 procedure
17 var
18 buffer : TMemoryStream;
19 bytesToWrite: integer;
20 randomGen : TGpRandom;
21 begin
22 randomGen := TGpRandom.Create;
23 try
24 while unwritten.Take(CBlockSize, bytesToWrite) do begin
25 buffer := TMemoryStream.Create;
26 buffer.Size := bytesToWrite;
27 FillBuffer(buffer.Memory, bytesToWrite, randomGen);
28 outQueue.Add(buffer);
29 end;
30 finally FreeAndNil(randomGen); end;
31 end
32 );
33 for buffer in outQueue do begin
34 memStr := buffer.AsObject as TMemoryStream;
35 output.CopyFrom(memStr, 0);
36 FreeAndNil(memStr);
37 end;
38 end;
The parallel part firstly creates a random generator in each task. Because the random generator code is not thread-safe, it cannot be shared between the tasks. Next it uses the above-mentioned Take pattern to grab a bunch of work, generates that much random data (inside the FillBuffer which is not shown here) and adds the buffer to the outQueue.
You may be asking yourself how will this code stop? When the unwritten counter drops to zero, Take will fail in every task and anonymous method running inside the task will exit. When this happens in all tasks, OnStop handler will be called automatically.
The code above passes Parallel.CompleteQueue to the OnStop. This is a special helper which creates a delegate that calls CompleteAdding on its parameter. Therefore, OnStop handler will call outQueue.CompleteAdding, which will cause the for loop in CreateRandomFile to exit after all data is processed.
7.7 Building a connection pool
The thread pool enables connection pooling by providing property ThreadData: IOtlThreadData to each task. This property is bound to a thread – it is created when a thread is created and is destroyed together with the thread.
To facilitate this, task implements property ThreadData which contains the user data associated with the thread.
1 type
2 IOmniTask = interface
3 ...
4 property ThreadData: IInterface;
5 end;
This data is initialized in the thread pool when a new thread is created. It is destroyed automatically when a thread is destroyed.
To initialize the ThreadData, write a ‘factory’ method, a method that creates a thread data interface. The thread pool will call this factory method to create the thread data and will then assign the same object to all tasks running in that thread.
1 type
2 TOTPThreadDataFactoryFunction = function: IInterface;
3 TOTPThreadDataFactoryMethod = function: IInterface of object;
4
5 IOmniThreadPool = interface
6 ...
7 procedure SetThreadDataFactory(
8 const value: TOTPThreadDataFactoryMethod); overload;
9 procedure SetThreadDataFactory(
10 const value: TOTPThreadDataFactoryFunction); overload;
11 end;
You can write two kinds of a thread data factories – a ‘normal’ function that returns an IInterface or a method function (a function that belongs to a class) that returns an IInterface.
7.7.1 From theory to practice
Let’s return to the practical part. In the database connection pool scenario, you’d have to write a connection interface, object and factory (see demo application 24_ConnectionPool for the full code).
In the OnCreate event the code creates a thread pool, assigns it a name and thread data factory. The latter is a function that will create and initialize new connection for each new thread. In the OnClose event the code terminates all waiting tasks (if any), allowing the application to shut down gracefully. FConnectionPool is an interface and its lifetime is managed automatically so we don’t have to do anything explicit with it.
1 procedure TfrmConnectionPoolDemo.FormCreate(Sender: TObject);
2 begin
3 FConnectionPool := CreateThreadPool('Connection pool');
4 FConnectionPool.SetThreadDataFactory(CreateThreadData);
5 FConnectionPool.MaxExecuting := 3;
6 end;
1 procedure TfrmConnectionPoolDemo.FormClose(Sender: TObject;
2 var Action: TCloseAction);
3 begin
4 FConnectionPool.CancelAll;
5 end;
The magic CreateThreadData factory just creates a connection object (which would in a real program establish a database connection, for example).
1 function TfrmConnectionPoolDemo.CreateThreadData: IInterface;
2 begin
3 Result := TConnectionPoolData.Create;
4 end;
There’s no black magic behind this connection object. It is an object that implements an interface. Any interface. This interface will be used only in your code. In this demo, TConnectionPoolData contains only one field – unique ID, which will help us follow the program execution.
1 type
2 IConnectionPoolData = interface
3 function ConnectionID: integer;
4 end;
5
6 TConnectionPoolData = class(TInterfacedObject, IConnectionPoolData)
7 strict private
8 cpID: integer;
9 public
10 constructor Create;
11 destructor Destroy; override;
12 function ConnectionID: integer;
13 end;
As this is not a code from a real world application, I didn’t bother connecting it to any specific database. TConnectionPoolData constructor will just notify the main form it has begun its job, generate a new ID and sleep for five seconds (to emulate establishing a slow connection). The destructor is even simpler, it just sends a notification to the main form.
1 constructor TConnectionPoolData.Create;
2 begin
3 PostToForm(WM_USER, MSG_CREATING_CONNECTION,
4 integer(GetCurrentThreadID));
5 cpID := GConnPoolID.Increment;
6 Sleep(5000);
7 PostToForm(WM_USER, MSG_CREATED_CONNECTION, cpID);
8 end;
9
10 destructor TConnectionPoolData.Destroy;
11 begin
12 PostToForm(WM_USER, MSG_DESTROY_CONNECTION, cpID);
13 end;
Creating and running a task is simple with the OmniThreadLibrary.
1 procedure TfrmConnectionPoolDemo.btnScheduleClick(Sender: TObject);
2 begin
3 Log('Creating task');
4 CreateTask(TaskProc).MonitorWith(OTLMonitor).Schedule(FConnectionPool);
5 end;
We are monitoring the task with the TOmniEventMonitor component because a) we want to know when the task will terminate and b) otherwise we would have to store into a global field a reference to the IOmniTaskControl interface returned from the CreateTask.
The task worker procedure TaskProc is again simple. First it pulls the connection data from the task interface (task.ThreadData as IConnectionPoolData), retrieves the connection ID and sends task and connection ID to the main form (for logging) and then it sleeps for three seconds, simulating heavy database activity.
1 procedure TaskProc(const task: IOmniTask);
2 begin
3 PostToForm(WM_USER + 1, task.UniqueID,
4 (task.ThreadData as IConnectionPoolData).ConnectionID);
5 Sleep(3000);
6 end;
Then … but wait! There’s no more! Believe it or not, that’s all. OK, there is some infrastructure code that is used only for logging but that you can look up by yourself.
There is also a code assigned to the second button (Schedule and wait) but it only shows how you can schedule a task and wait on its execution. This is useful if you’re running the task from a background thread.
7.7.2 Running the demo
Let’s run the demo and click on the Schedule key.
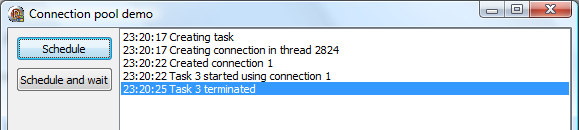
What happened here?
- Task was created.
- It was immediately scheduled for execution and thread pool called our thread data factory.
- Thread data object constructor waited for five seconds and returned.
- Thread pool immediately started executing the task.
- Task waited for three seconds and exited.
OK, nothing special. Let’s click the Schedule button again.
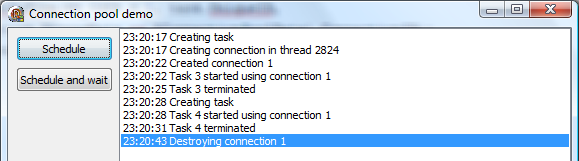
Now a new task was created (with ID 4), was scheduled for execution in the same thread as the previous task and reused the connection that was created when the first task was scheduled. There is no 5 second wait, just the 3 second wait implemented in the task worker procedure.
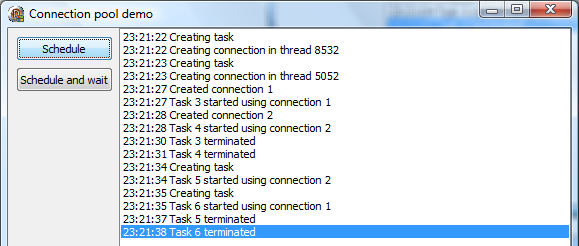
If you now let the program run for 10 seconds, a message ‘Destroying connection 1’ will appear. The reason for this is that the default thread idle timeout in a thread pool is 10 seconds. In other words, if a thread does nothing for 10 seconds, it will be stopped. You are, of course, free to set this value to any number or even to 0, which would disable the idle thread termination mechanism.
If you now click the Schedule button again, a new thread will be created in the thread pool and a new connection will be created in our factory function (spending 5 seconds doing nothing).
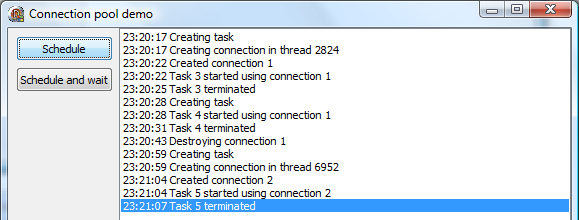
Let’s try something else. I was running the demo on my laptop with a dual core CPU, which caused the thread pool to limit maximum number of concurrently executing threads to two. By default, thread pool uses as much threads as there are cores in the system, but again you can override the value. (In releases up to [3.03], you could use at most 60 concurrently executing threads. Starting from release [3.04], this number is only limited by the system resources.)
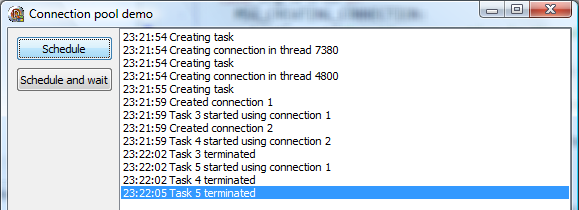
To recap – when running the demo, the thread pool was limited to two concurrent threads. When I clicked the Schedule button two times in a quick succession, the first task was scheduled and the first connection started being established (has entered the Sleep function). Then the second task was created (as the connection is being established from the worker thread, GUI is not blocked) and the second connection started being established in the second thread. Five seconds later, connections are created and tasks start running (and wait three seconds, and exit).
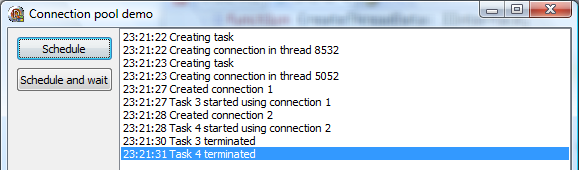
Then I clicked the Schedule button two more times. Two tasks were scheduled, and they immediately started execution in two worker threads.
For the third demo, I restarted the app and clicked the Schedule button three times. Only two worker threads were created and two connections established and two tasks started execution. The third task entered the thread pool queue and waited for the first task to terminate, after which it was immediately scheduled.
So here you have it – a very simple way to build a connection pool.
7.8 QuickSort and parallel max
The answer to both parts of the problem is the same – use the Fork/Join abstraction.
7.8.1 QuickSort
The first part of this how-to implements a well-known quicksort algorithm in a parallel way (see demo application 44_Fork-Join QuickSort for the full code).
Let’s start with a non-optimized single-threaded sorter. This simple implementation is easy to convert to the multi-threaded form.
1 procedure TSequentialSorter.QuickSort(left, right: integer);
2 var
3 pivotIndex: integer;
4 begin
5 if right > left then begin
6 if (right - left) <= CSortThreshold then
7 InsertionSort(left, right)
8 else begin
9 pivotIndex := Partition(left, right, (left + right) div 2);
10 QuickSort(left, pivotIndex - 1);
11 QuickSort(pivotIndex + 1, right);
12 end;
13 end;
14 end;
As you can see, the code switches to an insertion sort when the dimension of the array drops below some threshold. This is not important for the single-threaded version (it only brings a small speedup) but it will help immensely with the multi-threaded version.
Converting this quicksort to a multi-threaded version is simple.
Firstly, we have to create a Fork/Join computation pool. In this example, it is stored in a global field.
1 FForkJoin := Parallel.ForkJoin;
Secondly, we have to adapt the QuickSort method.
1 procedure TParallelSorter.QuickSort(left, right: integer);
2 var
3 pivotIndex: integer;
4 sortLeft : IOmniCompute;
5 sortRight : IOmniCompute;
6 begin
7 if right > left then begin
8 if (right - left) <= CSortThreshold then
9 InsertionSort(left, right)
10 else begin
11 pivotIndex := Partition(left, right, (left + right) div 2);
12 sortLeft := FForkJoin.Compute(
13 procedure
14 begin
15 QuickSort(left, pivotIndex - 1);
16 end);
17 sortRight := FForkJoin.Compute(
18 procedure
19 begin
20 QuickSort(pivotIndex + 1, right);
21 end);
22 sortLeft.Await;
23 sortRight.Await;
24 end;
25 end;
26 end;
The code looks much longer but changes are simple. Each recursive call to QuickSort is replaced with the call to Compute …
1 sortLeft := FForkJoin.Compute(
2 procedure
3 begin
4 QuickSort(left, pivotIndex - 1);
5 end);
… and the code Awaits on both subtasks.
Instead of calling QuickSort directly, parallel version creates IOmniCompute interface by calling FForkJoin.Compute. This creates a subtask wrapping the anonymous function which was passed to the Compute and puts this subtask into the Fork/Join computation pool.
The subtask is later read from this pool by one of the Fork/Join workers and is processed in the background thread.
Calling Await checks if the subtask has finished its work. In that case, Await returns and the code can proceed. Otherwise (subtask is still working), Await tries to get one subtask from the computation pool, executes it, and then repeats from the beginning (by checking if the subtask has finished its work). This way, all threads are always busy either with executing their own code or a subtask from the computation pool.
Because two IOmniCompute interfaces are stored on the stack in each QuickSort call, this code uses more stack space than the single-threaded version. That is the main reason the parallel execution is stopped at some level and simple sequential version is used to sort remaining fields.
7.8.2 Parallel max
The second part of this how-to finds a maximum element of an array in a parallel way (see demo application 45_Fork-Join max for the full code).
The parallel solution is similar to the quicksort example above with few important differences related to the fact that the code must return a value (the quicksort code merely sorted the array returning nothing).
This directly affects the interface usage – instead of working with IOmniForkJoin and IOmniCompute the code uses IOmniForkJoin<T> and IOmniCompute<T>. As our example array contains integers, the parallel code creates IOmniForkJoin<integer> and passes it to the ParallelMax function.
1 max := ParallelMax(Parallel.ForkJoin<integer>, Low(FData), High(FData));
In this example Fork/Join computation pool is passed as a parameter. This approach is more flexible but is also slightly slower and – more importantly – uses more stack space.
1 function ParallelMax(
2 const forkJoin: IOmniForkJoin<integer>;
3 left, right: integer): integer;
4
5 var
6 computeLeft : IOmniCompute<integer>;
7 computeRight: IOmniCompute<integer>;
8 mid : integer;
9
10 function Compute(left, right: integer): IOmniCompute<integer>;
11 begin
12 Result := forkJoin.Compute(
13 function: integer
14 begin
15 Result := ParallelMax(forkJoin, left, right);
16 end
17 );
18 end;
19
20 begin
21 if (right - left) < CSeqThreshold then
22 Result := SequentialMax(left, right)
23 else begin
24 mid := (left + right) div 2;
25 computeLeft := Compute(left, mid);
26 computeRight := Compute(mid + 1, right);
27 Result := Max(computeLeft.Value, computeRight.Value);
28 end;
29 end;
When the array subrange is small enough, ParallelMax calls the sequential (single threaded) version – just as the parallel QuickSort did, and because of the same reason – not to run out of stack space.
With a big subrange, the code creates two IOmniCompute<integer> subtasks each wrapping a function returning an integer. This function calls back ParallelMax (but with a smaller range). To get the result of the anonymous function wrapped by the Compute, the code calls the Value function. Just as with the Await, Value either returns a result (if it was already computed) or executes other Fork/Join subtasks from the computation pool.
7.9 Parallel search in a tree
The For Each abstraction can be used to iterate over complicated structures such as trees. The biggest problem is to assure that the code will always stop. The solution below achieves this by using special features of the blocking collection.
The solution to this problem is available as a demo application 35_ParallelFor.
The code in the demo application creates a big tree of TNode nodes. Each node contains a value (Value) and a list of child nodes (Child). TNode also implements a function to return the number of children (NumChild), a function that converts the node into a textual representation (ToString; used for printing out the result) and an enumerator that will allow us to access child nodes in a nice structured fashion (Children). To learn more about the implementation of TNode and its enumerator, see the demo program.
1 type
2 Node = class
3 Value: integer;
4 Child: array of TNode;
5 function NumChild: integer;
6 function ToString: string; reintroduce;
7 function Children: TNodeChildEnumeratorFactory;
8 end;
For comparison the demo program implements sequential search function SeqScan which uses recursion to traverse the tree.
1 function TfrmParallelForDemo.SeqScan(node: TNode;
2 value: integer): TNode;
3 var
4 iNode: integer;
5 begin
6 if node.Value = value then
7 Result := node
8 else begin
9 Result := nil;
10 for iNode := 0 to node.NumChild - 1 do begin
11 Result := SeqScan(node.Child[iNode], value);
12 if assigned(Result) then
13 break; //for iNode
14 end;
15 end;
16 end;
The parallel version of this function is more complicated. It uses a blocking collection that is shared between all ForEach tasks. This blocking collection contains all nodes that have yet to be traversed. At the beginning, it contains only the root node. Each task executes the following pseudo-code:
1 while <there are nodes in the blocking collection>
2 <take one node from the blocking collection>
3 <if the node contains the value we're searching for, stop>
4 <put all children of this node into the blocking collection>
The real code is more complicated because of two complications. Firstly, when a value is found, all ForEach tasks must stop, not just the one that had found the value. Secondly, the code must stop if the value we’re searching for is not present in the tree. In the pseudo-code above this is automatically achieved by the condition in the while statement but in reality this is not so easy. At some time the blocking collection may be empty when there is still data to be processed. (For example, just at the beginning when the first task takes out the root node of the tree. Yes, this does mean that the condition in the while statement above is not completely valid.)
1 function TfrmParallelForDemo.ParaScan(rootNode: TNode; value: integer): TNode;
2 var
3 cancelToken: IOmniCancellationToken;
4 nodeQueue : IOmniBlockingCollection;
5 nodeResult : TNode;
6 numTasks : integer;
7 begin
8 nodeResult := nil;
9 cancelToken := CreateOmniCancellationToken;
10 numTasks := Environment.Process.Affinity.Count;
11 nodeQueue := TOmniBlockingCollection.Create(numTasks);
12 nodeQueue.Add(rootNode);
13 Parallel.ForEach(nodeQueue as IOmniValueEnumerable)
14 .NumTasks(numTasks) // must be same number of task as in
15 // nodeQueue to ensure stopping
16 .CancelWith(cancelToken)
17 .Execute(
18 procedure (const elem: TOmniValue)
19 var
20 childNode: TNode;
21 node : TNode;
22 begin
23 node := TNode(elem.AsObject);
24 if node.Value = value then begin
25 nodeResult := node;
26 nodeQueue.CompleteAdding;
27 cancelToken.Signal;
28 end
29 else for childNode in node.Children do
30 nodeQueue.TryAdd(childNode);
31 end);
32 Result := nodeResult;
33 end;
The code first creates a cancellation token which will be used to stop the ForEach loop. Number of tasks is set to number of cores accessible from the process and a blocking collection is created.
Resource count for this collection is initialized to the number of tasks (numTasks parameter to the TOmniBlockingCollection.Create). This assures that the blocking collection will be automatically put into the ‘completed’ mode (as if the CompleteAdding had been called) if numTasks threads are simultaneously calling Take and the collection is empty. This prevents the ‘resource exhaustion’ scenario – if all workers are waiting for new data and the collection is empty, then there’s no way for new data to appear and the waiting is stopped by putting the collection into completed state.
The root node of the tree is added to the blocking collection. Then the Parallel.ForEach is called, enumerating the blocking collection.
The code also passes cancellation token to the ForEach loop and starts the parallel execution. In each parallel task, the following code is executed (this code is copied from the full ParaScan example above):
1 procedure (const elem: TOmniValue)
2 var
3 childNode: TNode;
4 node : TNode;
5 begin
6 node := TNode(elem.AsObject);
7 if node.Value = value then begin
8 nodeResult := node;
9 nodeQueue.CompleteAdding;
10 cancelToken.Signal;
11 end
12 else for childNode in node.Children do
13 nodeQueue.TryAdd(childNode);
14 end
The code is provided with one element from the blocking collection at a time. If the Value field is the value we’re searching for, nodeResult is set, blocking collection is put into CompleteAdding state (so that enumerators in other tasks will terminate blocking wait (if any)) and cancellation token is signalled to stop other tasks that are not blocked.
Otherwise (not the value we’re looking for), all the children of the current node are added to the blocking collection. TryAdd is used (and its return value ignored) because another thread may call CompleteAdding while the for childNode loop is being executed.
Parallel for loop is therefore iterating over a blocking collection into which nodes are put (via the for childNode loop) and from which they are removed (via the ForEach implementation). If child nodes are not provided fast enough, blocking collection will block on Take and one or more tasks may sleep for some time until new values appear. Only when the value is found, the blocking collection and ForEach loop are completed/cancelled.
7.10 Multiple workers with multiple frames
The solution to this problem can be split into three parts – the worker, the frame and the binding code in the form unit.
The solution to this problem is available as a demo application 49_FramedWorkers.
7.10.1 The worker
In this example (unit test_49_Worker in the demo application), the worker code is intentionally simple. It implements a timer which, triggered approximately every second, sends a message to the owner. This message is received in a Msg parameter when the task is created. The worker can also respond to a MSG_HELLO message with a 'Hello' response.
1 type
2 TFramedWorker = class(TOmniWorker)
3 strict private
4 FMessage: string;
5 public
6 function Initialize: boolean; override;
7 procedure MsgHello(var msg: TOmniMessage); message MSG_HELLO;
8 procedure Timer1;
9 end;
10
11 function TFramedWorker.Initialize: boolean;
12 begin
13 Result := inherited Initialize;
14 if Result then begin
15 FMessage := Task.Param['Msg'];
16 Task.SetTimer(1, 1000 + Random(500), @TFramedWorker.Timer1);
17 end;
18 end;
19
20 procedure TFramedWorker.MsgHello(var msg: TOmniMessage);
21 begin
22 Task.Comm.Send(MSG_NOTIFY, 'Hello, ' + msg.MsgData);
23 end;
24
25 procedure TFramedWorker.Timer1;
26 begin
27 Task.Comm.Send(MSG_NOTIFY, '... ' + FMessage);
28 end;
Message ID’s (MSG_HELLO, MSG_NOTIFY) are defined in unit test_49_Common as they are shared with the frame implementation.
7.10.2 The frame
The frame (unit test_49_FrameWithWorker) contains a listbox and a button. It implements a response function for the MSG_NOTIFY message – MsgNotify – and it contains a reference to the worker task. This reference will be set in the main form when the task and the frame are constructed.
1 type
2 TfrmFrameWithWorker = class(TFrame)
3 lbLog: TListBox;
4 btnHello: TButton;
5 procedure btnHelloClick(Sender: TObject);
6 private
7 FWorker: IOmniTaskControl;
8 public
9 property Worker: IOmniTaskControl read FWorker write FWorker;
10 procedure MsgNotify(var msg: TOmniMessage); message MSG_NOTIFY;
11 end;
The MsgNotify method is automatically called whenever the MSG_NOTIFY message is received by the frame. It merely shows the message contents.
1 procedure TfrmFrameWithWorker.MsgNotify(var msg: TOmniMessage);
2 begin
3 lbLog.ItemIndex := lbLog.Items.Add(msg.MsgData);
4 end;
A click on the button sends a MSG_HELLO message to the worker. A name of the frame is sent as a parameter. The worker will include this name in the response so we can verify that the response is indeed sent to the correct frame.
1 procedure TfrmFrameWithWorker.btnHelloClick(Sender: TObject);
2 begin
3 Worker.Comm.Send(MSG_HELLO, Name);
4 end;
7.10.3 The form
Five frame/worker pairs are created in the form while it is being created. The code in FormCreate creates and positions each frame and then creates a worker named Frame #%d (where %d is replaced with the sequential number of the frame). Workers are created in the CreateWorker method.
1 const
2 CNumFrames = 5;
3 CFrameWidth = 150;
4 CFrameHeight = 200;
5
6 function TfrmFramedWorkers.CreateFrame(left, top, width, height: integer;
7 const name: string): TfrmFrameWithWorker;
8 begin
9 Result := TfrmFrameWithWorker.Create(Self);
10 Result.Parent := Self;
11 Result.Left := left;
12 Result.Top := top;
13 Result.Width := width;
14 Result.Height := height;
15 Result.Name := name;
16 end;
17
18 procedure TfrmFramedWorkers.FormCreate(Sender: TObject);
19 var
20 frame : TfrmFrameWithWorker;
21 iFrame: integer;
22 begin
23 FTaskGroup := CreateTaskGroup;
24 for iFrame := 1 to CNumFrames do begin
25 frame := CreateFrame(
26 CFrameWidth * (iFrame - 1), 0, CFrameWidth, CFrameHeight,
27 Format('Frame%d', [iFrame]));
28 CreateWorker(frame, Format('Frame #%d', [iFrame]));
29 end;
30 ClientWidth := CNumFrames * CFrameWidth;
31 ClientHeight := CFrameHeight;
32 end;
The FormCreate method also creates a task group which is used to terminate all workers when a form is closed.
1 procedure TfrmFramedWorkers.FormDestroy(Sender: TObject);
2 begin
3 FTaskGroup.TerminateAll;
4 end;
The final piece of the puzzle is the CreateWorker method. It creates a low-level task and sets its name. The same name is assigned to the Msg parameter so that it will be used in messages sent from the task. The OnMessage call assigns the frame to function as a ‘message-processor’ for the tasks – all messages from the task will be dispatched to the frame. That’s how the MSG_NOTIFY message ends up being processed by the frame’s MsgNotify method.
1 procedure TfrmFramedWorkers.CreateWorker(frame: TfrmFrameWithWorker;
2 const caption: string);
3 var
4 worker: IOmniTaskControl;
5 begin
6 worker := CreateTask(TFramedWorker.Create(), caption)
7 .SetParameter('Msg', caption)
8 .OnMessage(frame)
9 .Run;
10 frame.Worker := worker;
11 FTaskGroup.Add(worker);
12 end;
The code above also assigns the worker to the frame and adds the worker to the task group.
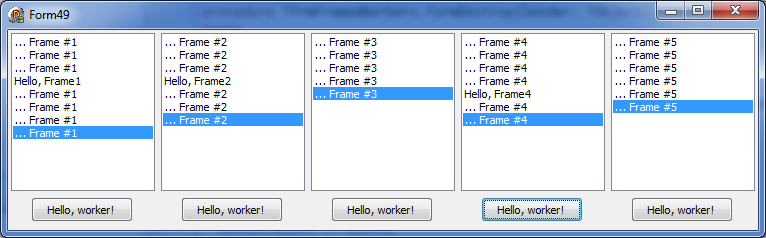
For a different approach to multiple workers problem see OmniThreadLibrary and databases.
7.11 OmniThreadLibrary and databases
Using databases with the OmniThreadLibrary can be quite simple at times; on the other hand, it can also be quite tricky. The main problem with databases is that you have to create database components in the thread that will be using them. As the visual components (as the TDBGrid) must be initialized from the main thread, this implies that you can’t directly connect database-aware GUI controls to database components.
Because of that, you have to devise a mechanism that transfers database data from the task to the main thread (and also – if the database access is not read-only – a mechanism that will send updates to the task so they can be applied to the database). In most cases this means you should ignore database-aware components and just build the GUI without them. In some cases, however, you could do a lot with splitting the existing database infrastructure at the correct point and leaving the GUI part almost unmodified. This example explores such an option.
An example is included with the OmniThreadLibrary distribution in the
examples/twofishfolder.
The basis for this article is the well-known Fish Facts demo program, included in Delphi’s Samples18 folder. This is a simple application that uses database-aware controls to display data from an InterBase database.
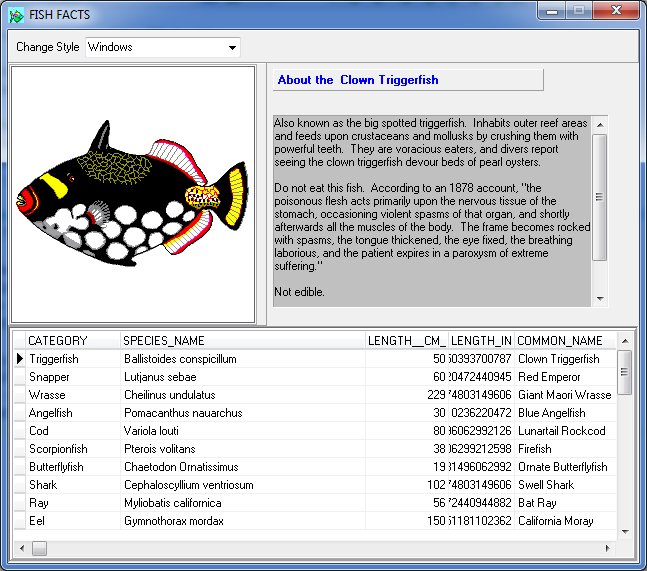
I have built a view-only version of Fish Facts called TwoFish which uses two frames, each containing data-aware controls and a background thread which accesses the InterBase data. Both frames are running in parallel and accessing the data at the same time.
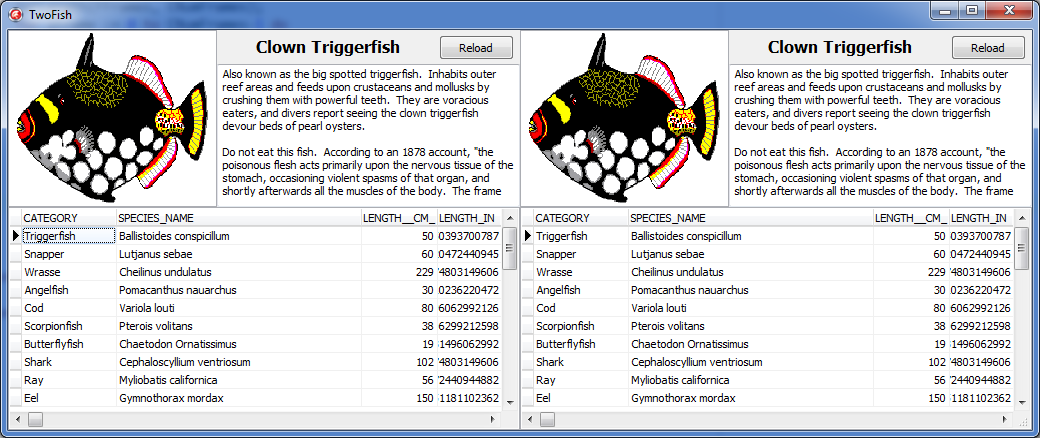
7.11.1 Database model
To create the TwoFish, I have copied Fish Facts components IBDatabase1, IBTransaction1 and IBTable1 into a data module twoFishDB. This data module contains no code, only these three components. I have also set IBDatabase1.Connected and IBTable1.Active to False.
Then I created the frame twoFishDB_GUI which uses the data module twoFishDB. This frame contains an unconnected TDataSource component DataSource1 and all data-aware components that are placed on the Fish Facts form – TDBGrid, TDBImage, TDBText and TDBMemo. They are all connected to the DataSource1.
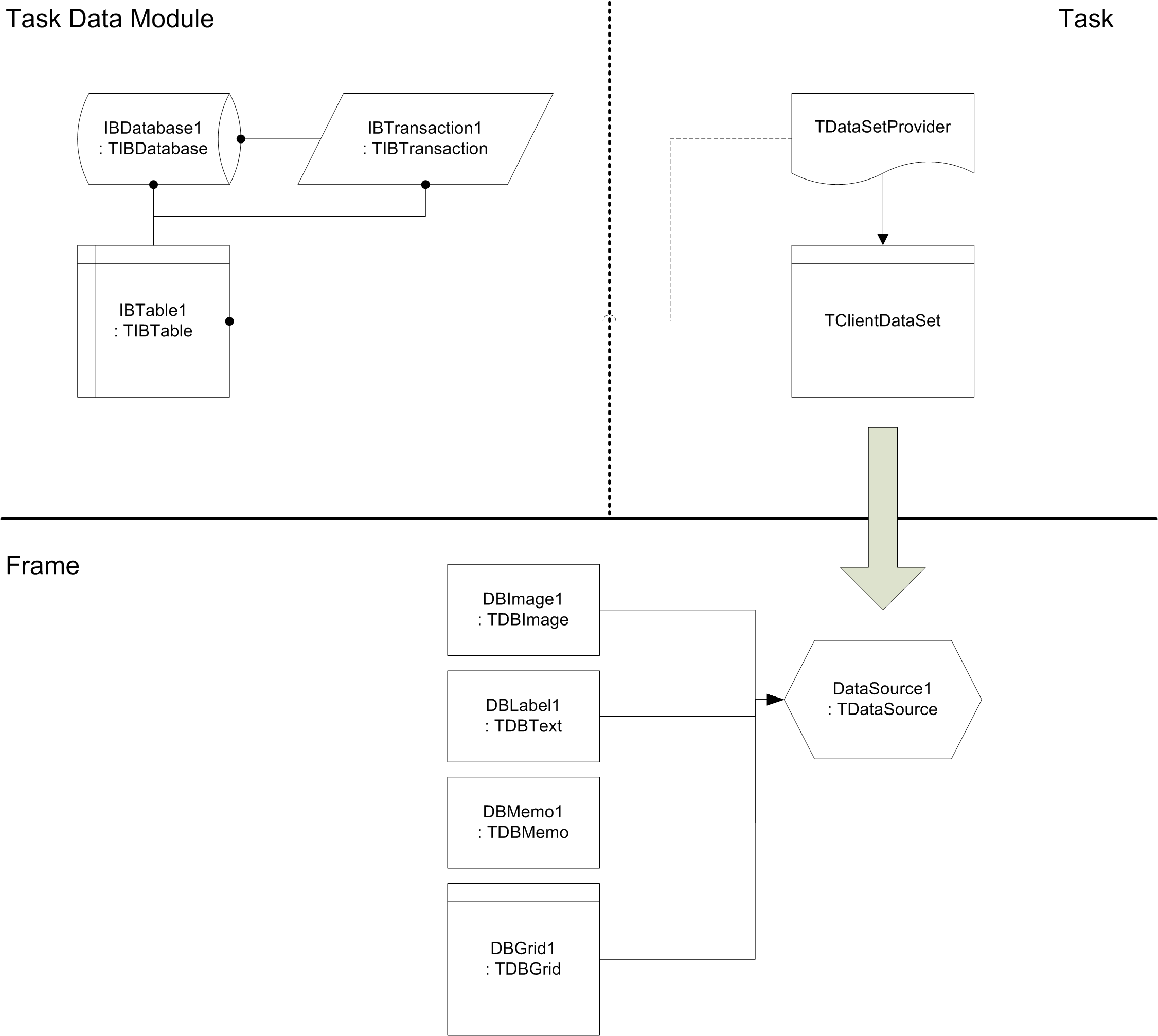
Main TwoFish program creates two frames. Each frame creates a Background Worker abstraction that (inside the worker task) creates the data module and activates database and database table (more details are given below).
When data is to be retrieved, the task creates a TClientDataSet and a TDataSetProvider which ‘pumps’ all data from the IBTable1 to the TClientDataSet. This client data set is then sent to the main form which connects it to the DataSource1. This automatically causes the data to be displayed in the data-aware controls. To keep the example simple, I have disabled data editing.
The most important points of this example are:
- Data module is initialized from the task, not from the frame’s event handlers. This way it is initialized in the thread that uses it.
- Data module is destroyed before the
OnDestroyis called (OnCloseQueryis used for this purpose). If you try to destroy the data module from theOnDestroy, a deadlock will occur inside the Delphi RTL code.
This example shows a different approach to frame-task interaction than the Multiple workers with multiple frames – here the background worker is managed by the frame itself, not by the main form.
7.11.2 Frame and worker
The frame wraps one background task that operates on the database and contains database-aware controls displaying the database data.
The Background Worker abstraction is created in the AfterConstruction method and destroyed in the BeforeDestruction method. AfterConstruction creates a background worker and specifies task initializer and finalizer (.Initialize and .Finalize). Delegates provided to these two functions (InitializeDatabase and FinalizeDatabase) are called when background worker task is created and before it is destroyed.
1 procedure TfrmTwoFishDB_GUI.AfterConstruction;
2 begin
3 inherited;
4 FWorker := Parallel.BackgroundWorker
5 .Initialize(InitializeDatabase)
6 .Finalize(FinalizeDatabase)
7 .Execute;
8 end;
9
10 procedure TfrmTwoFishDB_GUI.BeforeDestruction;
11 begin
12 CloseConnection;
13 inherited;
14 end;
15
16 procedure TfrmTwoFishDB_GUI.CloseConnection;
17 begin
18 if assigned(FWorker) then begin
19 FWorker.Terminate(INFINITE);
20 FWorker := nil;
21 end;
22 FreeAndNil(FDataSet);
23 end;
You may have noticed that no code was provided to execute work items. The reason behind this is that the background worker will execute different types of requests. Instead of writing if ... then tests to detect the work item type and trigger appropriate code, we’ll pass the executor function together with each request.
BeforeDestruction destroys the background worker and destroys the FDataSet component (we’ll see later why it is used).
Task initializer and finalizer are also very simple – they just create and destroy the data module. The data module is accessible to the background worker through the taskState variable.
1 procedure TfrmTwoFishDB_GUI.FinalizeDatabase(const taskState: TOmniValue);
2 begin
3 FreeAndNil(FDataModule)
4 end;
5
6 procedure TfrmTwoFishDB_GUI.InitializeDatabase(var taskState: TOmniValue);
7 begin
8 FDataModule := TdmTwoFishDB.Create(nil);
9 taskState := FDataModule;
10 end;
7.11.2.1 Connecting to the database
Data controls are initially in an unconnected state. They are only connected when the public method OpenConnection is called.
1 procedure TfrmTwoFishDB_GUI.OpenConnection(const databaseName: string;
2 onConnectionOpen: TNotify);
3 begin
4 FWorker.Schedule(
5 FWorker.CreateWorkItem(databaseName),
6 FWorker.Config.OnExecute(ConnectToDatabase).OnRequestDone(
7 procedure (const Sender: IOmniBackgroundWorker;
8 const workItem: IOmniWorkItem)
9 begin
10 if assigned(onConnectionOpen) then
11 onConnectionOpen(Self, workItem.FatalException);
12 end
13 ));
14 end;
OpenConnection schedules a work request that contains the database name as a parameter. It also sets the executor function (ConnectToDatabase) and an anonymous function that will be executed after the request is processed (OnRequestDone). This anonymous function returns the result of the request to the OpenConnection caller by calling the onConnectionOpen parameter. [Result in this case is exposed as an exception that is triggered if the database connection cannot be established. If the connection can be made, the workItem.FatalException function will return nil.]
The important fact to note is that the OnExecute parameter (ConnectToDatabase) is called from the worker thread and the OnRequestDone parameter (the anonymous function) is called from the thread that created the frame (the main thread).
1 procedure TfrmTwoFishDB_GUI.ConnectToDatabase(
2 const workItem: IOmniWorkItem);
3 var
4 dataModule: TdmTwoFishDB;
5 begin
6 dataModule := (workItem.TaskState.AsObject as TdmTwoFishDB);
7 GTwoFishLock.Acquire; //probably only necessary if using InterBase driver
8 try
9 dataModule.IBDatabase1.DatabaseName := workItem.Data.AsString;
10 dataModule.IBDatabase1.Connected := true;
11 finally GTwoFishLock.Release; end;
12 end;
The data module associated with the worker is accessed through the workItem.TaskState property which gives you access to the taskState variable initialized in the InitializeDatabase method. Database name is taken from the work item parameter (workItem.Data). The database name is set in the IBDatabase component and connection is established (Connected := true). If the connection fails, an exception will be raised. This exception is caught by the OmniThreadLibrary and stored in the workItem object where it is later processed by the anonymous method in the OpenConnection method.
The weird Acquire/Release pair is here because of bugs in the gds32.dll – the dynamic library that handles connection to the InterBase. It turns out that gds32 handles parallel connections to the database perfectly well – as long as they are not established at the same time. In other words – you can communicate with the database on multiple connections at the same time (get data, put data, execute SQL commands …) but you cannot establish connections in parallel. Sometimes it will work, sometimes it will fail with a mysterious access violation error in the gds32 code. That’s why the twoFishDB_GUI unit uses a global critical section to prevent multiple connections to be established at the same time. 19
1 var
2 GTwoFishLock: TOmniCS;
7.11.2.2 Retrieving the data
To retrieve data from the database, main unit calls the Reload function. This function is also called inside the frame from the click event on the Reload button.
Reload just schedules a work request without any input. To process the request, LoadData will be called.
1 procedure TfrmTwoFishDB_GUI.Reload;
2 begin
3 FWorker.Schedule(
4 FWorker.CreateWorkItem(TOmniValue.Null),
5 FWorker.Config.OnExecute(LoadData).OnRequestDone(DisplayData)
6 );
7 end;
LoadData executes in the background worker thread. It uses a temporary TDataSetProvider to copy data to a freshly created TClientDataSet20. During this process, a ‘Field not found’21 exception is raised twice. If you run the program in the debugger, you’ll see this exception four times (twice for each frame). You can safely ignore the exception as it is handled internally in the Delphi RTL and is not visible to the end-user.
At the end, the TClientDataSet that was created inside the LoadData is assigned to the workItem.Result. It will be processed (and eventually destroyed) in the main thread.
1 procedure TfrmTwoFishDB_GUI.LoadData(const workItem: IOmniWorkItem);
2 var
3 dataModule : TdmTwoFishDB;
4 resultDS : TClientDataSet;
5 tempProvider: TDataSetProvider;
6 begin
7 dataModule := (workItem.TaskState.AsObject as TdmTwoFishDB);
8 if not dataModule.IBTable1.Active then
9 dataModule.IBTable1.Active := true
10 else
11 dataModule.IBTable1.Refresh;
12
13 resultDS := TClientDataSet.Create(nil);
14
15 tempProvider := TDataSetProvider.Create(nil);
16 try
17 tempProvider.DataSet := dataModule.IBTable1;
18 resultDS.Data := tempProvider.Data;
19 finally FreeAndNil(tempProvider); end;
20
21 workItem.Result := resultDS; // receiver will take ownership
22 end;
The DisplayData method executes in the main thread after the request was processed (i.e., the data was retrieved). If there was an exception inside the work item processing code (LoadData), it is displayed. Otherwise, the TClientDataSet is copied from the workItem.Result into an internal TfrmTwoFishDB_GUI field and assigned to the DataSource1.DataSet. By doing that, all data-aware controls on the frame can access the data.
1 procedure TfrmTwoFishDB_GUI.DisplayData(
2 const Sender: IOmniBackgroundWorker;
3 const workItem: IOmniWorkItem);
4 begin
5 FreeAndNil(FDataSet);
6
7 if workItem.IsExceptional then
8 ShowMessage('Failed to retrieve data. ' +
9 workItem.FatalException.Message)
10 else begin
11 FDataSet := workItem.Result.AsObject as TClientDataSet;
12 DataSource1.DataSet := FDataSet;
13 end;
14 end;
7.11.3 Main program
The main program is fairly simple. In the OnCreateEvent two frames are created. Frame references are stored in the FFrames form field, declared as array of TfrmTwoFishDB_GUI.
1 procedure TfrmTwoFish.FormCreate(Sender: TObject);
2 var
3 iFrame: integer;
4 begin
5 SetLength(FFrames, CNumFrames);
6 for iFrame := 0 to CNumFrames-1 do
7 FFrames[iFrame] := CreateFrame(
8 CFrameWidth * iFrame, 0, CFrameWidth, CFrameHeight,
9 Format('Frame%d', [iFrame+1]));
10 ClientWidth := CNumFrames * CFrameWidth;
11 ClientHeight := CFrameHeight;
12 OpenConnections;
13 end;
Next, the form is resized to twice the frame size and OpenConnections is called to establish database connections in all frames.
1 procedure TfrmTwoFish.OpenConnections;
2 var
3 frame: TfrmTwoFishDB_GUI;
4 begin
5 for frame in FFrames do
6 frame.OpenConnection(CDatabaseName ,
7 procedure (Sender: TObject; FatalException: Exception)
8 begin
9 if assigned(FatalException) then
10 ShowMessage('Failed to connect to the database!')
11 else
12 (Sender as TfrmTwoFishDB_GUI).Reload;
13 end);
14 end;
OpenConnections iterates over all frames and calls OpenConnection method in each one. Two parameters are passed to it – the database name and an anonymous method that will be executed after the connection has been established.
If the connection fails, the FatalException field will contain the exception object raised inside the background worker’s OpenConnection code. In such a case, it will be logged. Otherwise, the connection was established successfully and Reload is called to load data into the frame.
Frames are destroyed from OnCloseQuery. It turns out that Delphi (at least XE2) will deadlock if data modules are destroyed in background threads while OnDestroy is running.
1 procedure TfrmTwoFish.FormCloseQuery(Sender: TObject;
2 var CanClose: boolean);
3 var
4 frame: TfrmTwoFishDB_GUI;
5 begin
6 for frame in FFrames do
7 frame.CloseConnection;
8 end;
To recapitulate, most important facts about using databases from secondary threads are:
- Always create non-visual database components in the thread that will be using them.
- Always create data-aware controls in the main thread.
- Never connect data-aware controls to non-visual database components that were created in a secondary thread.
- Wrap
TIBDatabase.Connected := truein a critical section because of gds32 bugs. - Destroy database tasks from
OnCloseQuery, not fromOnDestroyif you are using data modules in a secondary thread. - Establish some mechanism of data passing between the database (secondary thread) and the view (main thread).
7.12 OmniThreadLibrary and COM/OLE
It is actually very simple – you have to remember to call CoInitializeEx and CoUninitialize from the task code and then you won’t have any problems.
I have put together a simple example that uses SOAP to retrieve VAT info for European companies using the SOAP service at ec.europa.eu. It is included with the OmniThreadLibrary distribution in the examples/checkVat folder.
The program has two input fields, one for the country code (inpCC) and one for the VAT number (inpVat), a button that triggers the SOAP request (btnCheckVat) and a memo that displays the result (outVatInfo).
There’s only one method – the btnCheckVat.OnClick handler.
1 procedure TfrmCheckVat.btnCheckVatClick(Sender: TObject);
2 begin
3 btnCheckVat.Enabled := false;
4 outVatInfo.Lines.Clear;
5 FRequest := Parallel.Future<checkVatResponse>(
6 function: checkVatResponse
7 var
8 request: checkVat;
9 begin
10 OleCheck(CoInitializeEx(nil, COINIT_MULTITHREADED));
11 try
12 request := checkVat.Create;
13 try
14 request.countryCode := Trim(inpCC.Text);
15 request.vatNumber := Trim(inpVat.Text);
16 Result := checkVatService.GetcheckVatPortType.checkVat(request);
17 finally FreeAndNil(request); end;
18 finally CoUninitialize; end;
19 end,
20 Parallel.TaskConfig.OnTerminated(
21 procedure (const task: IOmniTaskControl)
22 begin
23 outVatInfo.Text := FRequest.Value.name_ + #13#10 +
24 FRequest.Value.address;
25 FRequest := nil;
26 btnCheckVat.Enabled := true;
27 end
28 )
29 );
30 end;
This method firstly disables the button (so that only one request at a time can be active) and clears the output. Then it uses a Future returning a checkVatResponse (a type defined in the checkVatService unit which was generating by importing the WSDL specification). This Future will execute the SOAP request in a background task and after that the anonymous method in Parallel.TaskConfig.OnTerminated will be called in the main thread. This anonymous method displays the result in the outVatInfo control, destroys the FRequest Future object and enables the button.
The main Future method looks just the same as if it would be executed from the main thread except that the SOAP stuff is wrapped in CoInitializeEx/CoUninitialize calls that make sure that everything is correctly initialized for COM/OLE.
7.13 Using a message queue with a TThread worker
The simplest way is to create two TOmniMessageQueue objects, one to send data to a thread and one to receive data. Alternatively, you could create a TOmniTwoWayChannel, which is just a simple pair of two TOmniMessageQueue instances. The solution below uses a former approach.
A solution to this problem is included with the OmniThreadLibrary distribution in the
examples/TThread communicationfolder.
We have to handle two very similar but not identical parts:
- Sending data from any thread (main or background) to a
TThreadbased worker. - Sending data from any
TThreadbased worker or from a form to the main thread (to a form).
Let’s deal with them one by one.
7.13.1 Sending data from multiple producers to a single worker
To send data form a form to a thread, we need a message queue. This example uses a TOmniMessageQueue object for that purpose. An instance of this object is created in the main thread. All threads – the main thread, the worker threads, and potential other data-producing threads – use the same shared object which is written with thread-safety in mind.
7.13.1.1 Initialization and cleanup
The TOmniMessageQueue constructor takes a maximum queue size for a parameter. TWorker is just a simple TThread descendant which accepts the instance of the message queue as a parameter so it can read from the queue.
1 FCommandQueue := TOmniMessageQueue.Create(1000);
2 FWorker := TWorker.Create(FCommandQueue);
The shutdown sequence is fairly standard. Stop is used instead of Terminate so it can set internal event which is used to signal the thread to stop.
1 if assigned(FWorker) then begin
2 FWorker.Stop;
3 FWorker.WaitFor;
4 FreeAndNil(FWorker);
5 end;
6 FreeAndNil(FCommandQueue);
7.13.1.2 Sending data to the worker
To put data into a queue, use its Enqueue method. It accepts a TOmniMessage record. Each TOmniMessage contains an integer message ID (not used in this example) and a TOmniValue data which, in turn, can hold any data type.
1 procedure TfrmTThreadComm.Query(value: integer);
2 begin
3 if not FCommandQueue.Enqueue(TOmniMessage.Create(0 {ignored}, value)) then
4 raise Exception.Create('Command queue is full!');
5 end;
Enqueue returns False if the queue is full. (A TOmniMessageQueue can only hold as much elements as specified in the constructor call.)
The example below shows how everything works correctly if two threads are started (almost) at the same time and both write to the message queue.
1 var
2 th1: TThread;
3 th2: TThread;
4 begin
5 th1 := TThread.CreateAnonymousThread(
6 procedure
7 begin
8 Query(Random(1000));
9 end);
10 th2 := TThread.CreateAnonymousThread(
11 procedure
12 begin
13 Query(Random(1000));
14 end);
15
16 th1.Start;
17 th2.Start;
18 end;
7.13.1.3 Receiving the data
The worker’s Execute method waits on two handles in a loop. If a FStopEvent (an internal event) is signalled, the loop will exit. If the message queue’s GetNewMessageEvent (a THandle-returning method) gets signalled, a new data has arrived to the queue. In that case, the code loops to empty the message queue and then waits again for something to happen.
1 procedure TWorker.Execute;
2 var
3 handles: array [0..1] of THandle;
4 msg : TOmniMessage;
5 begin
6 handles[0] := FStopEvent.Handle;
7 handles[1] := FCommandQueue.GetNewMessageEvent;
8 while WaitForMultipleObjects(2, @handles, false, INFINITE) =
9 (WAIT_OBJECT_0 + 1) do
10 begin
11 while FCommandQueue.TryDequeue(msg) do begin
12 //process the message ...
13 end;
14 end;
15 end;
7.13.2 Sending data from a worker to a form
To send messages from a worker thread to a form, we need another instance of TOmniMessageQueue. As we can’t wait on a handle in the main thread (that would block the user interface), we’ll use a different notification mechanism – a window message observer.
7.13.2.1 Initialization and cleanup
We create the queue just as in the first part. To use a window message observer we then just have to assign a message handler to the queue’s OnMessage event. An observer will be set up automatically in the background.
After that, the event handler will be called once for each message that is inserted into the queue from any thread (or from the form itself).
1 FResponseQueue := TOmniMessageQueue.Create(1000, false);
2 FResponseQueue.OnMessage := HandleThreadMessage;
While shutting down, we just have to destroy the queue.
1 FreeAndNil(FResponseQueue);
7.13.2.2 Sending data to the form
To send a data, we use exactly the same approach as in the first part (sending data to a worker).
1 if not FResponseQueue.Enqueue(TOmniMessage.Create(0 {ignored},
2 Format('= %d', [msg.MsgData.AsInteger * 2])))
3 then
4 raise Exception.Create('Response queue is full!');
7.13.2.3 Receiving the data
On the receiving side (the form) we have to write an event handler that is called for each message.
1 procedure TfrmTThreadComm.HandleThreadMessage(Sender: TObject; const msg: TOmniMessage);
2 begin
3 //msg.MsgID is ignored in this demo
4 //msg.MsgData contains a string, generated by the worker
5 lbLog.ItemIndex := lbLog.Items.Add(msg.MsgData);
6 end;